
Overview
Once stored procedures deployed to production server, there is no easy way to safely debug or reproduce or tracking issues if we haven’t had a proper error and exception handling logic.
In this article, we’ll give one of example to catch the errors and save related information to table for issue debugging.
Handling errors using TRY…CATCH
Here’s how the syntax looks like. It’s pretty simple to get the hang of. We have two blocks of code:
BEGIN TRY
--function logic
END TRY
BEGIN CATCH
--error handling logic
END CATCHThe code BEGIN TRY and END TRY is our function logic code that we want to monitor for an error. So, if an error would have happened inside this TRY statement, the CATCH statement will be triggered and then we need to handle those errors inside of CATCH statement . We can try to report the error, log the error, or event fix the error. But in this article, we are going to demo how to log the error, so we know can when it happened, who did it and other useful stuff. We even have access to some special data only available inside the CATCH statement:
- ERROR_NUMBER – Returns the internal number of the error
- ERROR_STATE – Returns the information about the source
- ERROR_SEVERITY – Returns the information about anything from informational errors to errors user of DBA can fix, etc.
- ERROR_LINE – Returns the line number at which an error happened on
- ERROR_PROCEDURE – Returns the name of the stored procedure or function
- ERROR_MESSAGE – Returns the most essential information and that is the message text of the error
The script below is as simple as it gets:
-- Basic example of TRY...CATCH
BEGIN TRY
-- Generate a divide-by-zero error
SELECT
1 / 0 AS Error;
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_STATE() AS ErrorState,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_PROCEDURE() AS ErrorProcedure,
ERROR_LINE() AS ErrorLine,
ERROR_MESSAGE() AS ErrorMessage;
END CATCH;
GOThis is an example of how it looks and how it works. The only thing we’re doing in the BEGIN TRY is dividing 1 by 0, which will cause an error. If we execute the script from above, this is what we get:
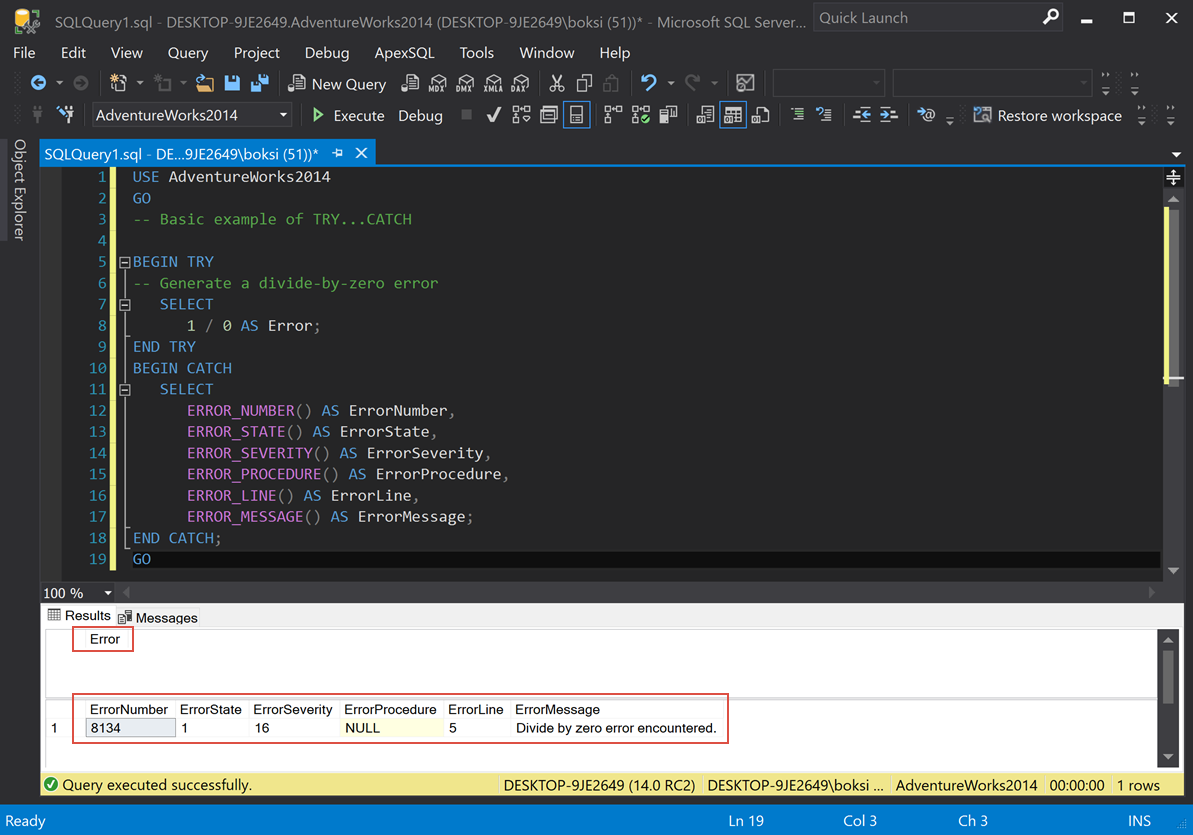
From left to right, we got ErrorNumber, ErrorState, ErrorSeverity; there is no procedure in this case (NULL), ErrorLine, and ErrorMessage.
Now, let’s create a table called DB_Errors, which can be used to store tracking data:
CREATE TABLE DB_Errors
(ErrorID INT IDENTITY(1, 1),
UserName VARCHAR(100),
ErrorNumber INT,
ErrorState INT,
ErrorSeverity INT,
ErrorLine INT,
ErrorProcedure VARCHAR(MAX),
ErrorMessage VARCHAR(MAX),
ErrorDateTime DATETIME)
GONow, let’s modify a custom stored procedure from the database and put an error handler in there:
ALTER PROCEDURE dbo.AddSale @employeeid INT,
@productid INT,
@quantity SMALLINT,
@saleid UNIQUEIDENTIFIER OUTPUT
AS
SET @saleid = NEWID()
BEGIN TRY
INSERT INTO Sales.Sales
SELECT @saleid,@productid,@employeeid,@quantity
END TRY
BEGIN CATCH
INSERT INTO dbo.DB_Errors
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE());
END CATCH
GO
Altering this stored procedure simply wraps error handling in this case around the only statement inside the stored procedure. If we call this stored procedure and pass some valid data, here’s what happens:
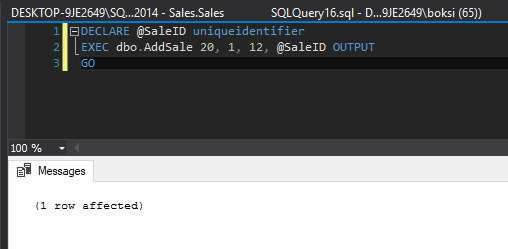
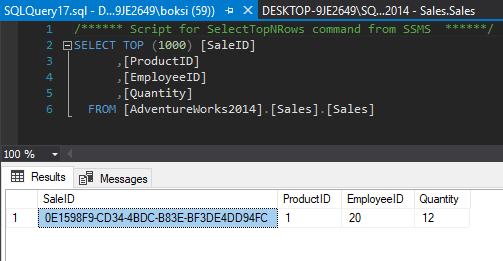
A quick Select statement indicates that the record has been successfully inserted:
However, if we call the above-stored procedure one more time, passing the same parameters, the results grid will be populated differently:
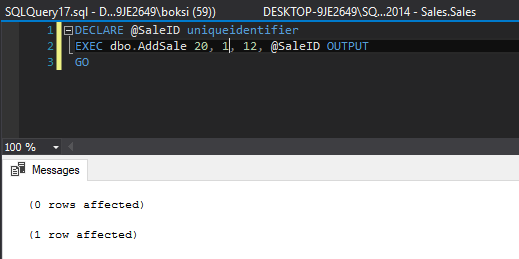
This time, we got two indicators in the results grid:
0 rows affected – this line indicated that nothing actually went into the Sales table
1 row affected – this line indicates that something went into our newly created logging table
So, what we can do here is look at the errors table and see what happened. A simple Select statement will do the job:
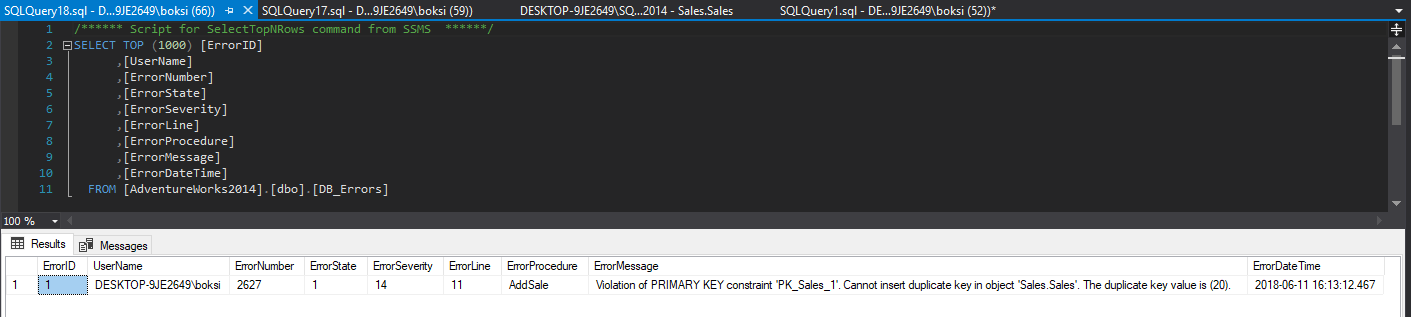
Here we have all the information we set previously to be logged, only this time we also got the procedure field filled out and of course the SQL Server “friendly” technical message that we have a violation:
Violation of PRIMARY KEY constraint ‘PK_Sales_1′. Cannot insert duplicate key in object’ Sales.Sales’. The duplicate key value is (20).
So in this way, we have tracking what the error happened and then can fix issue based on the error information which make our issue tracking and fixing task more easily.