CHECKSUM function returns the checksum value computed over a table row, or over an expression list.
BINARY_CHECKSUM returns the binary checksum value computed over a row of a table or over a list of expressions.
HASHBYTES returns the MD2, MD4, MD5, SHA, SHA1, or SHA2 hash of its input in SQL Server.For SQL Server 2014 (12.x) and earlier, allowed input values are limited to 8000 bytes. Beginning with SQL Server 2016 (13.x), all algorithms other than SHA2_256, and SHA2_512 are deprecated.
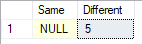
BINARY_CHECKSUM and CHECKSUM return different values for the string data types, where locale can cause strings with different representation to compare as equal.
However, CHECKSUM and BINARY_CHECKSUM cannot is not guaranteed the values in the expression list is changed. It’s better to use HASHBYTES instead.
Examples
If we have an incoming row of data (let’s say @column1, @column2, @column3, @column4) and I want to know if the incoming values match the ones already in the table and update the table only if they are different, what’s the best way to do that/
You might think that’s easy and you’d just add a WHERE clause to your UPDATE like:
Where Column1 = @column1
and Column2 = @column2
and Column3 = @column3
and Column4 = @column4
If you have large number of columns then you can imagine what this looks like. In addition, you may need to handle the the NULL value if column are nullable like this:
( ISNULL(Column1,'') = ISNULL(@column1,'')
The easier way to do this is by adding one more column that represents a checksum or hash value for all the columns then just compare that one field. The remain question is about which checksum or hashing function to use. Based on the information I mentioned in the above, the checksum and binary_checsum cannot guarantee the result is correct. Therefore hashbytes is the better options to do this job.
HASHBYTES('SHA2_256',
CONCAT(@column1, '|',
@column2, '|',
@column3, '|',
@column4,'|' ))
Tips: add a separator ‘|’ character between columns to allow for empty strings