
Index is used to speed-up query performance in SQL Server. It is similar to book or dictionary indexes. In the book, if you are looking for some particular chapter, you can looking the index and get the page number of the chapter then go directly to that page. Without index, it will take long time for you to find the desired chapter.
The similar logic for the database index. Well-designed indexes can reduce disk I/O operations and consume fewer system resources therefore improving query performance. In SQL Server table can have two types of indexes:
- Clustered Indexes
Clustered index is as same as dictionary where the data is arranged by alphabetical order. The order clustered indexes stored the table or view data rows in the table is the order of key values order. Each table can have 1 clustered indexes only, because it can have one kind of order in the same. In SQL Server, the primary key constraint automatically creates a clustered index on that particular column.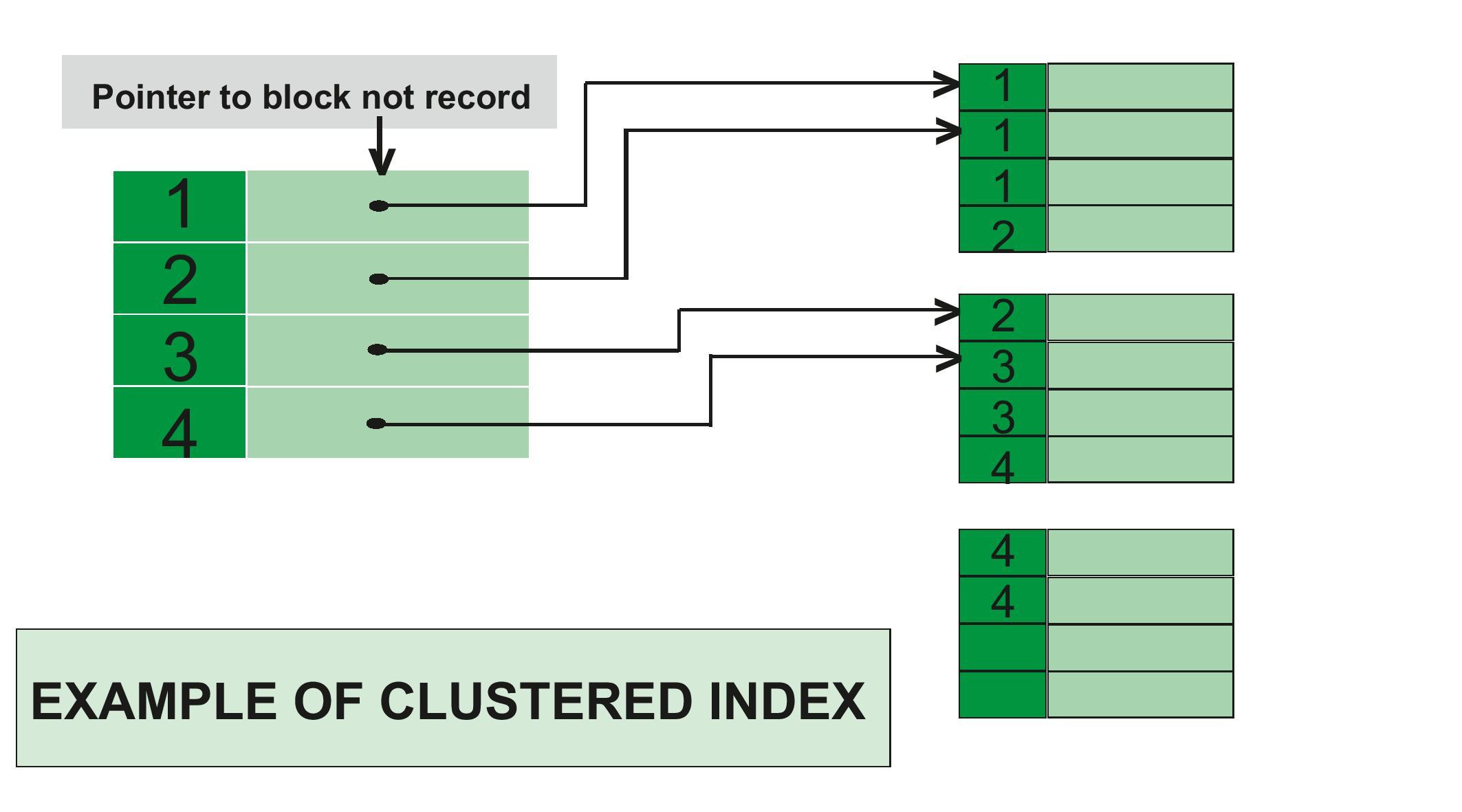
Example of clustered index
CREATE DATABASE schooldb
CREATE TABLE student
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
DOB datetime NOT NULL,
total_score INT NOT NULL,
city VARCHAR(50) NOT NULL
)
The primary key of column ‘id’ will become clustered index automatically. You use system procedure “sp_helpindex” to see the indexes of the table.
USE schooldb
EXECUTE sp_helpindex student
Another way to view table indexes is by going to “Object Explorer-> Databases-> Database_Name-> Tables-> Table_Name -> Indexes”.
Non-clustered Indexes
Non-Clustered Index is similar to the index of textbook. The index of textbook listed the chapter name and related page number, you can directly go to the page by using the page number of the chapter if you are looking for some particular one.
The data and index are stored in different place. Therefore you can have multiple non-clustered index for each table, all the index will point to the same storage place. 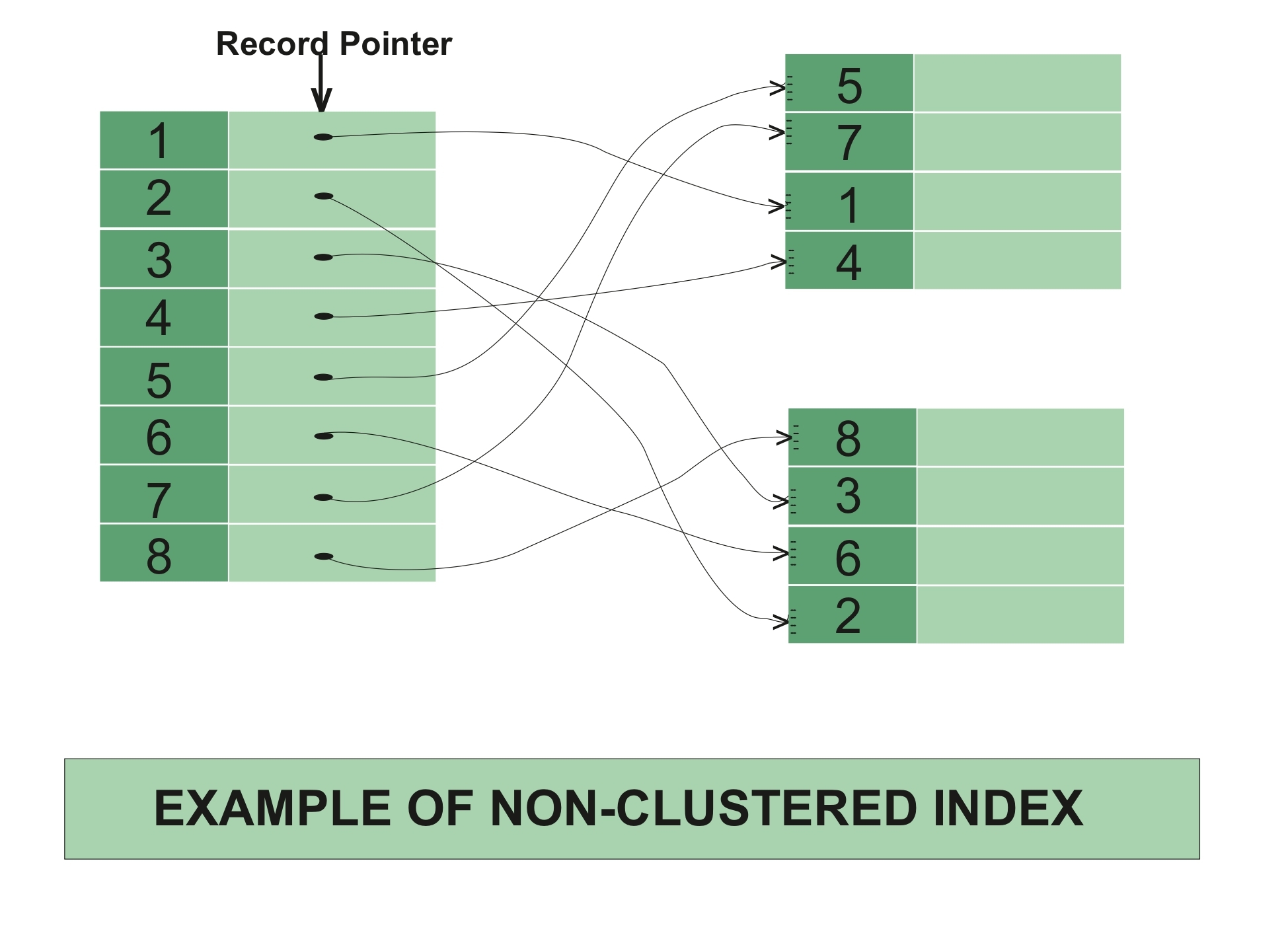
To create a new clustered Index, execute the following script:
use schooldb
CREATE CLUSTERED INDEX IX_tblStudent_Gender_Score
ON student(gender ASC, total_score DESC)
Differences
differences between clustered and non-clustered indexes.
- Can only have one clustered index per table. However, We can create multiple non-clustered indexes on the same table.
- Clustered indexes only sort tables. Therefore, they do not consume extra storage. Non-clustered indexes are stored in a separate place from the actual table claiming more storage space.
- Clustered indexes are faster than non-clustered indexes since they don’t involve any extra lookup step.
- In clustered index, the clustered key defines order of data within table. In non-clustered index, the index key defines the order of data in the index only.